
Tesla’s Big Bet: Cameras over LiDAR for Self Driving Cars
Is Tesla’s camera-first self driving approach better than LiDAR? And what autonomous vehicles can learn from superhuman chess engines.

There are two schools of thought when it comes to sensing systems for autonomous vehicles:
Using LiDAR, radar, ultrasonic and camera sensors (or a combination of these)
Using camera sensors only and nothing else.
LiDAR stands for Light Detection and Ranging. It's like microwave radar, but using much shorter wavelengths (850—1550 nm) gives increased spatial resolution for driving decisions. Its downside is high cost. Waymo’s Generation 5 self driving taxi has a sticker price of about $200,000, and the Generation 6 is estimated to be lower cost, but still uses 13 cameras, 4 lidar, 6 radar and a whole lot of audio receivers.
Tesla and Elon Musk have made some bold decisions in going with the camera-only approach to avoid expensive sensor hardware, but they are yet to deliver on their promise of a Cybercab that can operate in even limited geographical areas, let alone with a promised price tag of $30,000. Teslas with Full Self Driving (FSD) using vision only sensing already have a poor disengagement rate at one intervention every 13 miles.
Current expert opinion is that the camera-only approach will fail to deliver unsupervised self-driving, and that sensor redundancy is the only logical way to have a safe self-driving solution at scale. As much as evidence from companies such as Waymo and Cruise shows that LiDAR technology is essential to self driving, reality is a bit more nuanced.
In this post, we explore both LiDAR and camera-based approaches to self driving, and draw parallels with machine intelligence in competitive chess.
Self-driving with pure-vision
Teaching machines to drive like humans
Driving data knows best
Bitter Lessons and Moravec’s Paradox
Stockfish and AlphaZero
Read time: 13 mins
The Dream of Pure-Vision
Since 2022, the Full Self Driving (FSD) option in Teslas have been camera-based only, without relying on ultrasonic, radar or LiDAR systems. Despite concerns with how safe this actually is, Elon Musk has been a strong proponent of the low-cost camera-based approach which he states is the only feasible way to build autonomous vehicles at scale, and that companies using LiDAR are doomed for using a short term crutch that raises the entropy of the system. Recently China’s Xpeng motors has also adopted the Tesla approach and abandoned LiDAR systems to go fully camera-based.
Musk is not against LiDAR technology per-se. SpaceX has developed its own in-house LiDAR sensors for the Crew Dragon which used it to dock with the International Space Station. His opinion is that the high cost of LiDAR is useful in such scenarios, but is overkill for automotive applications.
The main argument for vision-only approach is how humans actually drive. We use vision as primary input (and some hearing assistance) with a finely honed perception network (our brain) that allows us to drive with a reasonably good road sense. Assuming that is actually possible, if we were to train neural networks based on vast amounts of actual driving data, then it should suffice to have a vision-only approach to self driving. Here is Tesla’s ex-director of AI, Andrej Karpathy, explaining why vision is necessary and sufficient for self-driving.
Teaching Machines to Drive Like Humans
An arguably obvious way to teach machines to drive is to enable it to see like humans do. When we drive, we can quickly categorize objects on the road into vehicles, people, road signs and hazards. Based on our prior experience, we have a pre-built understanding of how these objects behave and we use it to make driving decisions. For example: “There is a rock on the side of the road, but it’s not going to move" or “There is a child up ahead who is likely going to do something unpredictable.”
In essence, this is the concept on which LiDAR systems are traditionally built around. The entire process from sensing the environment to generating control actions for driving are broken down into modules, each with its unique function.

Sensing: Generates a 3D representation of a scene using the reflections from LiDAR pulses, and measuring the time of arrival of each pulse, to create a 3D representation of the scene called a 3D point cloud. Camera based techniques can also be used to build a 3D scene from 2D sensor data, but depth estimations are not often good enough. There is also the issue of low light conditions and real time data processing of high resolution images.

A 3D point cloud from a LiDAR sensor. Source: NVIDIA. Map Creation: There are two kinds of maps needed. A real-time map of the 3D surroundings, and a static map related to traffic rules such as road/lane boundaries, lights and signs that are generated offline with high precision. The creation of predefined maps is in conflict with the ultimate vision of unsupervised self driving because it is impractical to create such massively detailed maps everywhere in the world. But it does work for limited geographical regions.
Localization: Based on the map, this module places the autonomous vehicle into the map and provides context to the environment surrounding the vehicle.
Perception: This module performs the critical step of “seeing” like a human. It categorizes, identifies and tracks objects in the 3D point cloud. Here is a dynamic view of object perception using LiDAR, video credits Robosense.ai.
Routing/Planning: These modules chart out the route from source to destination and then plan out a trajectory that the car should follow based on its immediate surroundings.
Control: This is the actual execution of driving that involves controlling steering, brakes and acceleration.

Traditional autonomous driving algorithms like the above have been rule-based, dictating what the system can and cannot do. The heuristics that guide the boundaries of rule-based systems are developed based on human driving experience. The downsides of such a system include the error from each module adding up, and compute not be used effectively.
In real life, there are simply too many possible situations that do not fit into a rule-based guidance system. This is inherently an incomplete approach because we cannot build a framework around why we make the driving decisions we do. It is often the spontaneous output of a trained perception system in our brains. The more driving experience we have and the more data we collect, the better our driving decisions are.
End-to-End Autonomy: Data Knows Best
An alternative to a rule-based driving system is a data-driven one. By sampling a huge amount of driving decisions made by humans, the training data could be used to train a neural network that is essentially a "raw sensor data in, control out" system. This is called an end-to-end autonomous system. It does not attempt to perceive, classify, and track objects like a perception system does. It is far simpler in concept. It takes in image sensor data and uses a black-box neural network to generate control outputs.
Tesla has been collecting egregious amounts of driving data from the millions of cars they have sold, and are currently in operation. The on-board electronics operates in shadow mode continuously making driving predictions when people are driving, and when there significant deviations of prediction from reality, a snapshot of the data is stored and uploaded to Tesla servers as “Gateway log” files that contain information about Autopilot, cruise control, and even whether drivers had their hands on the wheel. These gateway log files are stored on a microSD card that records data only a few times a second, allowing cards to store years worth of driving data on board. Collecting massive amounts of data, especially related to crashes addresses the long tail problem of self driving, where rare events can lead to potentially disastrous results, but need to be prevented anyway.
Tesla’s approach of fleet learning is something few other companies can do since they do not have the ability to collect data from a large number of cars currently operating in real-world conditions spread out over many geographical regions. There are other vision-based concerns related to glare from the sun, and cameras getting dirty but these are more trivial problems solved with redundant camera systems. The real challenge lies in training the AI system well enough to operate reliably.
In Stratechery's excellent article, Ben Thompson tells the story of Richard Bowles of Arianespace, who was asked in 2013 by a reporter about Musk’s dream of $15 million launches using reusable rockets (Ariane 5 costs $178 million per launch in 2023). Bowles dismisses the question saying it is nothing but a dream from which people will have to wake up on their own. The dream of reusable rockets has allowed over a hundred Falcon 9 rocket launches in 2024 with SpaceX charging in the ballpark of $67 million per launch. Is pure-vision self driving another dream we are being dismissive about? Just like Bowles, it is hard to tell from where we are, considering that the engineering challenges involved are entirely different.
Bitter Lessons and Moravec’s Paradox
Thompson also cites Rich Sutton's blog post The Bitter Lesson, which makes the case that systems built around human expert knowledge seem to pan out in the short term, and not betting on compute hurts the evolution of technology in the long run.
… researchers always tried to make systems that worked the way the researchers thought their own minds worked — they tried to put that knowledge in their systems — but it proved ultimately counterproductive, and a colossal waste of researcher's time, when, through Moore's law, massive computation became available and a means was found to put it to good use.
By using LiDAR 3D point clouds and perception algorithms to identify objects and make predictions, one could argue that we making the same mistake of trying to build in human knowledge into machines. There are many examples where leveraging search, computation, and in today’s world, data (as Thompson argues), has provided extraordinary results.
Perception is a hard problem considering that our brains have an entire lobe that has evolved for thousands of years to become the finely tuned perception machine it is today. As Hans Moravec pointed out in 1988, there is big difference in capability between how machines handle intelligence versus perception tasks. Moravec’s paradox states,
It is comparatively easy to make computers exhibit adult level performance on intelligence tests or playing checkers, and difficult or impossible to give them the skills of a one-year-old when it comes to perception and mobility.
Autonomous Driving and Chess Engines
To make an analogy between autonomous driving and chess, both require foresight for possible futures, a real-time knowledge of the current environment, and decision making to meet a specified end goal. The analogy is inherently imperfect because of Moravec’s paradox, and also because the cost of a wrong move has vastly different consequences. Let us just entertain it anyway.
The rise of chess engines since the early demonstration of IBM’s Deep Blue Supercomputer which played games against Gary Kasparov is an interesting starting point. Deep Blue’s approach was a mix of software running on general purpose processors, application specific hardware called chess accelerators which calculated possible moves and outcomes, and human experience via chess grandmasters who worked with programmers to fine tune machine limitations. IBM’s Deep Blue AI expert, Murray Campbell explained in a Scientific American article that the 1997 version of Deep Blue that defeated Kasparov in just 19 moves could rapidly search through 100-200 million positions per second.
![World chess champion Garry Kasparov [left] playing against IBM's supercomputer Deep Blue in 1996 during the ACM Chess Challenge in Philadelphia.](https://substackcdn.com/image/fetch/$s_!RzDF!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F9a63fb8d-1ecc-464e-ad21-3d2d092d4673_1200x900.jpeg "World chess champion Garry Kasparov [left] playing against IBM's supercomputer Deep Blue in 1996 during the ACM Chess Challenge in Philadelphia.")
The brute force approach of massive search upset the chess world at the time, who argued that this is not how real chess is played. Instead it leverages compute to perform tasks more efficiently as Sutton points out. It is estimated that Deep Blue’s ELO score (a number that quantifies relative chess skill) at the time was about 2900, while Kasparov’s was 2812. Pretty close, considering that they used vastly different playing styles.
Autonomous driving is in the pre-Deep Blue era of its time. There have been many approaches adopted to transform 3D point cloud data from LiDAR into meaningful driving decisions. Convolutional neural networks apply learning techniques on groups of pixels, PointNet based methods handle apply deep learning to individual 3D points, and Graph-based methods leverage spatial relationships among 3D points. But fundamentally, LiDAR-based learning techniques tend to emulate the human driving experience, rather than leveraging raw data. Regardless of LiDAR or vision technology, leveraging search, learning and data could be the key to accelerate progress towards unsupervised self driving.
Stockfish and AlphaZero
At the risk of pushing the chess-driving analogy beyond its sensible limits, it is instructive to look at the best chess engine today, Stockfish 17. Stockfish has an ELO rating of 3704, while the highest rating ever achieved by a human is by Magnus Carlsen at 2882. An 800+ point lead for Stockfish over Carlsen means that there is almost no chance of Carlsen ever beating Stockfish, and the game might at best end in a draw.
Stockfish uses an Efficiently Updatable Neural Network (NNUE), which was introduced into chess as a proof-of-concept by Japanese mathematician Hisayori Noda aka nodchip in 2019. NNUE is different from a deep convolutional neural network (CNN) that other chess engines such as Lc0 use in that it updates the neural network based on chess positions already evaluated. A deep CNN with many neuron layers takes massive resources to compute, but NNUE only uses four hidden layers, is capable of massive positional calculations on much less capable hardware. Good articles have been written that explain NNUE well. The point is NNUE does not use traditional concepts of chess instead relying on the evaluation of 100 million positions per second without the need for expensive GPU hardware.
AlphaZero is an algorithm introduced by Google’s DeepMind in 2017 that reaches superhuman levels of gameplay in chess, Shogi and Go, purely by self-play and reinforcement learning. Starting from no strategic knowledge of the game (only rules), AlphaZero outperformed Stockfish in just 4 hours by playing 300k games with itself.
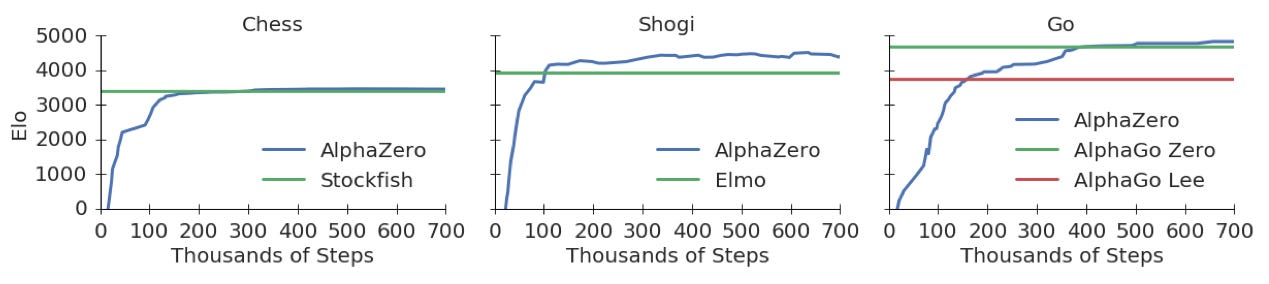
When the gameplay of these machines are observed, they are seen to make moves that human experience deems suboptimal, but they turn out right in the context of a game many moves ahead. Technology has fundamentally changed the way these games are played. Experts now rely on engines to analyze games and suggest improvements, and may be the only way a human will break the ceiling of a 3000+ ELO score in the future.
The near-perfection of gameplay engines represents the pinnacle of self driving capability of autonomous vehicles — a vision of where we would like to be in the future. By purely leveraging search, data and self-learning from sensor data, we may be able to achieve superhuman levels of driving that results in zero traffic-related deaths and injuries. Chess engines have taken 25+ years to get to where they are today but autonomous vehicle technology is still in its infancy. Only time will tell if Tesla’s camera-only approach with massive amounts of driving data is enough to create the AlphaZero of autonomous learning and driving. In the meantime, we just might need LiDAR, radar and ultrasonic sensors to get us there.
If you like this post, please click ❤️ on Substack, subscribe to the publication, and tell someone if you like it. 🙏🏽
If you enjoyed this issue, reply to the email and let me know your thoughts, or leave a comment on this post.
We have a community of professionals, enthusiasts and students in our Discord server where we chat about a variety of topics. Join us!
The views, thoughts, and opinions expressed in this newsletter are solely mine; they do not reflect the views or positions of my employer or any entities I am affiliated with. The content provided is for informational purposes only and does not constitute professional or investment advice.
Vision may not be the perfect solution to the problem, only that human's used it as our solution due to the limits of human perception. One could argue that using other ways of sensing the world including vision and lidar but using the same data based approach will end up being superior, it doesn't require it to be rules based by default if using Lidar.
Many times I have read the argument, which you reiterate here, that "for a safe system you need Lidar" or "you cannot have a safe system with just a camera". I just don't understand why people connect "safety" with "Lidar", why? Safety of a system (tesla fsd, waymo, whatever) should be evaluated by a series of standardized tests, basically you take the AI to a driving test similar like people get a driving license. This has nothing to do with underlaying technology. (Personally I believe that lidar+cameras and also just cameras will both work ok, obviously together with a machine learning core, and not a rule-based system.)